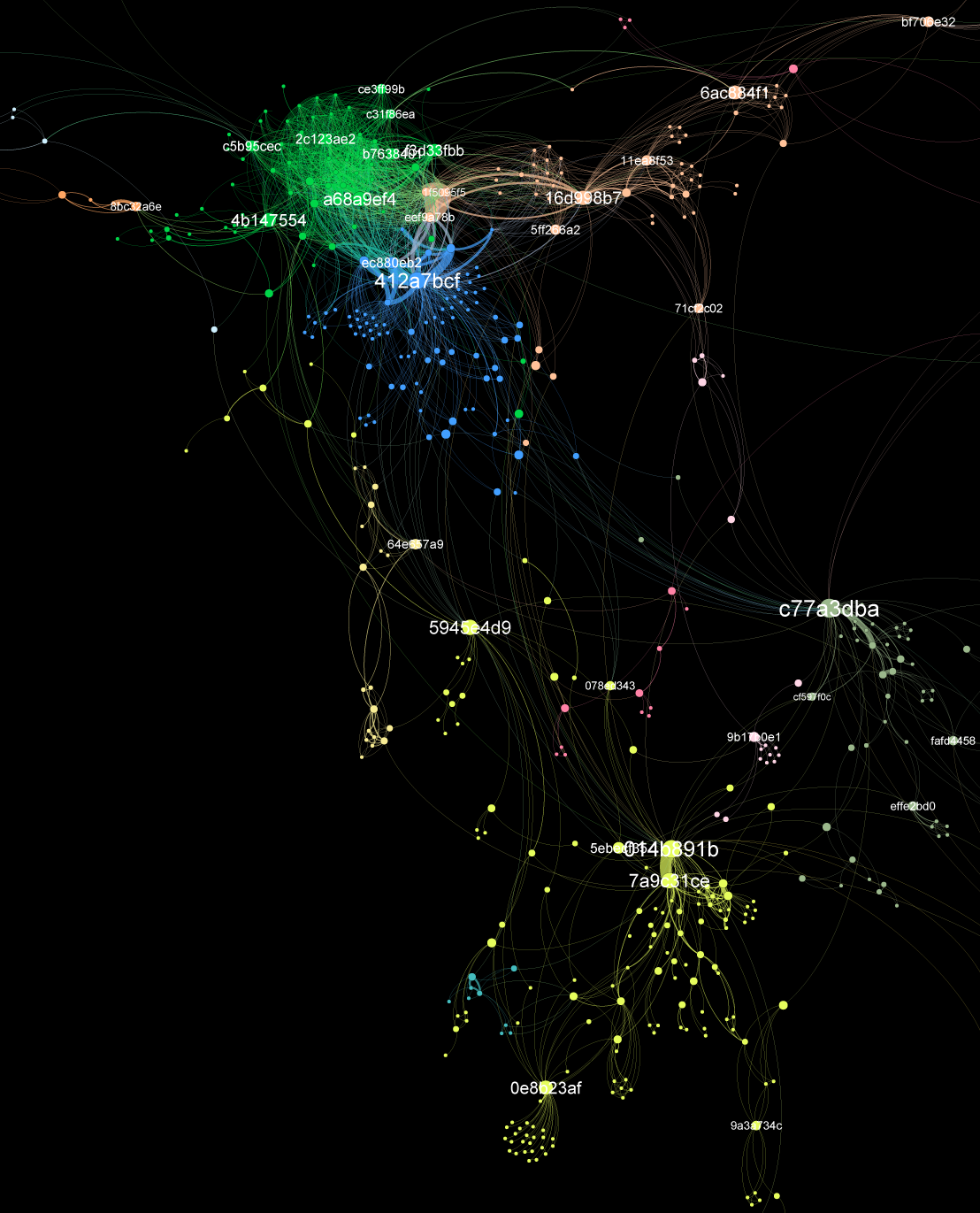
Week 7: Network Analysis and Web Mentions
Greetings! This week I dug a bit deeper into the citation data, created some additional visuals, and looked into some tools to scrape mentions of DataONE on the web. (I refer a lot to “citing” and “cited” articles in this post so here’s a clarification: citing = all articles that Continue reading Week 7: Network Analysis and Web Mentions