
Happy 4th of July, everyone
Main tasks for me in this week is to build an SQLite for future analysis, dive deeper and try to figure out how Galaxy Group collect information and added tags, additionally, continue reading the papers related to “provenance”, “reproducibility” and “workflow” in the corpus.
Where are these tags come from?
To ensure the reproducibility and also the legality to analyze these papers, we email the group member of the Galaxy Project. Hope we can get the answer soon.
As for the tags automatically generated by Zotero, some interesting points have been found. By comparing the information of one paper in Galaxy Collection and personal Zotero Group, the big difference except who added this paper existed in library catalog and tags.


Furthermore, by going to the website where this paper published, we confirmed that automatically generated tags come from the keywords provided by the publisher. One thing attracts our attention is that these tags lost their provenance, which could be our further research topic. For example, the tags come from IEEE Xplore actually should be divided into four categories including IEEE Keywords, INSPEC: Controlled Indexing, INSPEC: Non-Controlled Indexing, and Author Keywords.
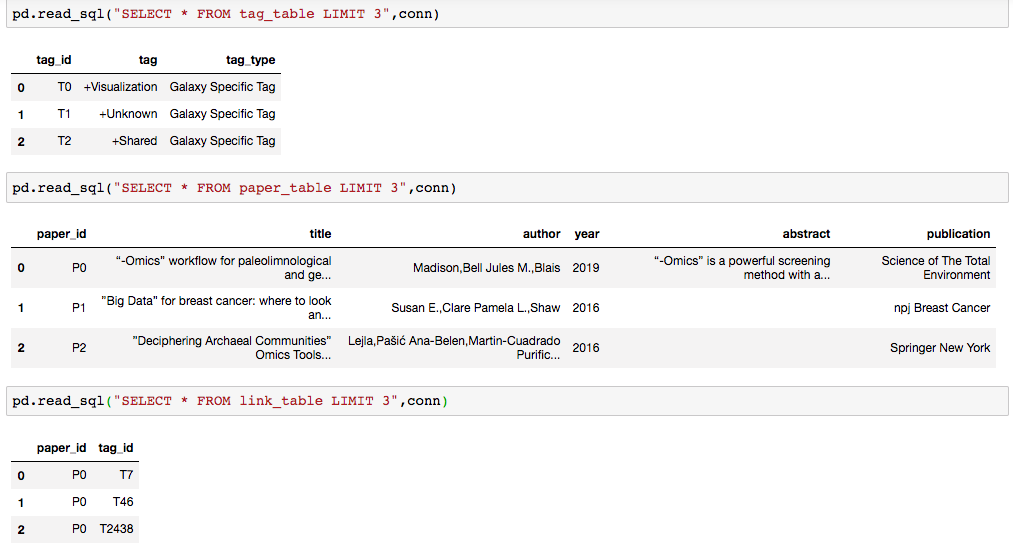
SQLite for Galaxy Zotero Corpus
SQL is always a good language to analyze data and ER-diagram could present the data much clearer. Through several transformations, the final database comes out.
Database V1.0 contains three tables named paper_table, link_table, tag_table. For paper_table, it contains six attributes including paper_id, title, author, year, abstract and publication. paper_id is the primary key. In tag_table, three attributes are included tag_id, tag_name, and tag_type. To connect these two tables, link_table is created which contains paper_id and tag_id.
Paper reading
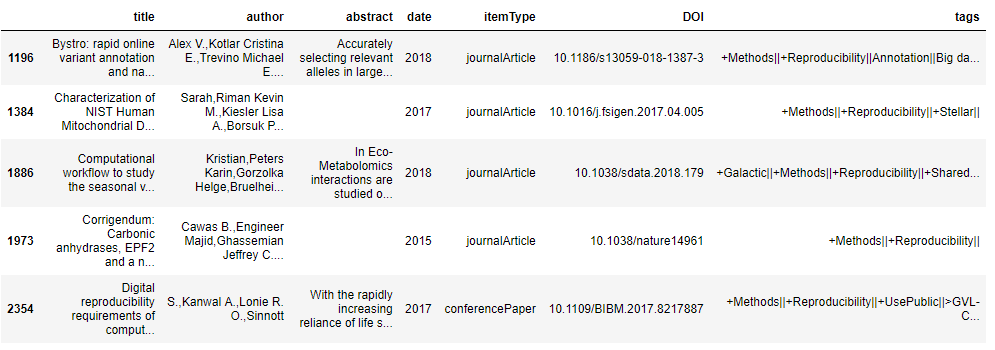
The number of papers under these chosen tags(‘+Methods’, ‘Reproducibility’)is:5
The number of papers under these chosen tags(‘Reproducibility’, ‘Workflow’)is:7
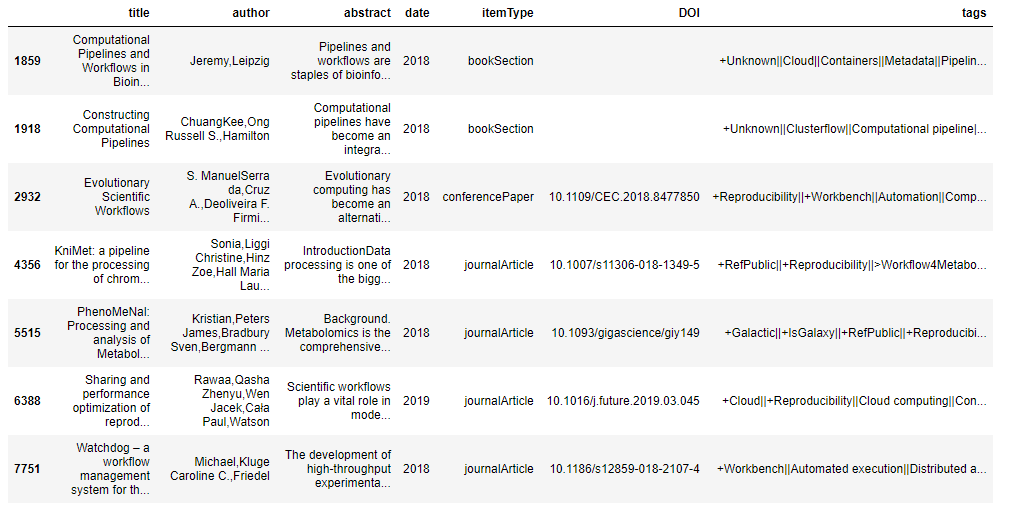
Reading for these 12 papers will be finished next week.