
Over the past week, our group’s focus has been on implementation work for OPeNDAP’s provenance browser. The approach we’ve taken relies upon three types of data:
- Sample provenance records for OPeNDAP’s server processing.
- Records describing OPeNDAP modules called by the server.
- Developers responsible for maintaining modules.
Each of these three types of data has been loaded into our project RDF triple store based on Prizms – an RPI-developed toolkit designed to aid in the generation of linked open data. For entries (2) and (3), Prizms generates RDF records based on the following web-accessible spreadsheets:
OPeNDAP Modules: https://docs.google.com/spreadsheet/ccc?key=0An84UEjofnaydFRrUF9YWk03Y3NHNjJqUEg0NUhUZXc&usp=drive_web#gid=0
OPeNDAP Developers: https://docs.google.com/spreadsheet/ccc?key=0ArTeDpS4-nUDdHdqU3ZFREQ4LTA1aGxJR2o2S1BFeWc&usp=drive_web#gid=0
OpenLink Virtuoso, our RDF triple store, is capable of returning results in varying formats (XML,CSV,JSON) which can in-turn be used to generate human-readable presentations. Using XML encodings of query results, we are now applying a set of XSLT transformations to generate description pages for various forms of content. Below are some screenshots with accompanying descriptions.
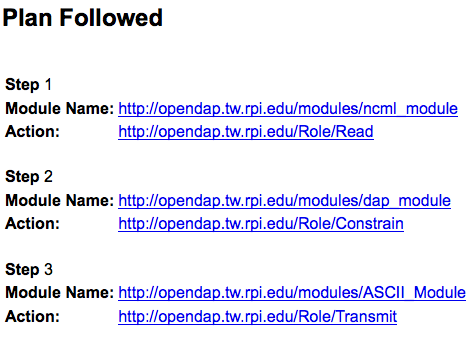
An OPeNDAP plan – the sequence of modules called during a given session, along with individual roles for those modules.
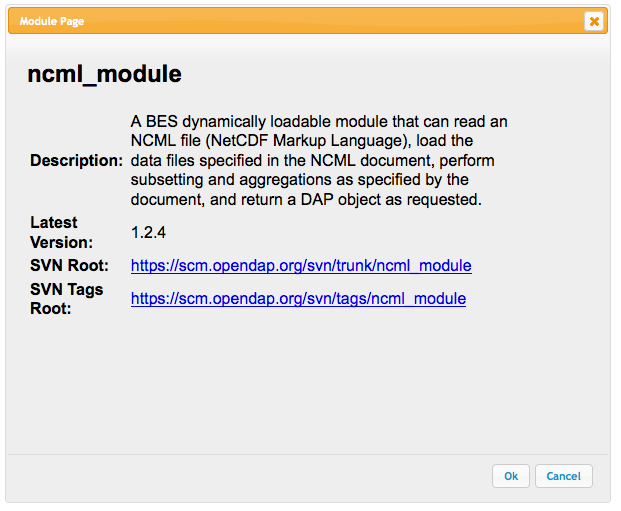
A description page for the OPeNDAP NCML Module.
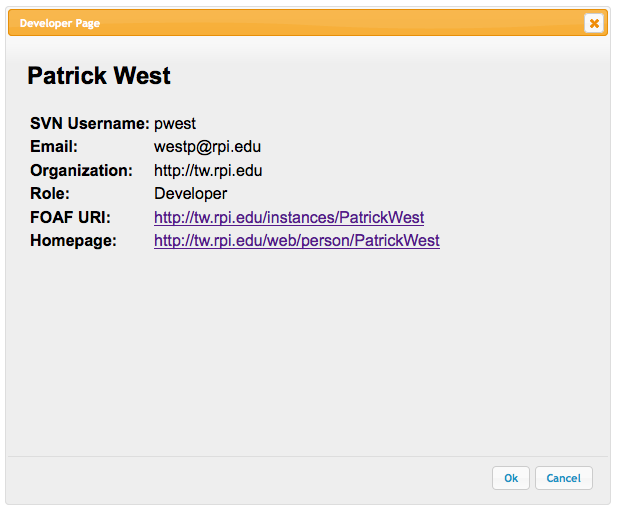
A description page for Patrick West – one of the developers for the NCML Module.
Although these were just screen shots for the splash pages (modules and people), this is providing us with a great look and feel for what we want to present to the community. We want to be able to show the concept of Linked Data that could be generated by the OPeNDAP Back-End Server (BES), citation and attribution information, licensing, and more.
We are also utilizing csv2rdf4lod, a tool developed by another graduate student here at the Tetherless World Constellation Tim Lebo, that can take the google docs spread sheets, in csv format, convert that to RDF that can be used in linked open dada (LOD). This is just one possible use for csv2rdf4lod.
James’ work on developing the provenance browser, though incomplete, is instrumental in the overall work that we are doing in data visualization and linked open data. More to come in the following months.