
Hello world!
Professor Bertram is out for conference this week, so this week I mainly focused on reviewing the previous work I had done and dive deeper into the related terminologies or model structure by reading a bunch of papers. To stabilize what I have done in the last three weeks, a mind map had been created for my reference, which made my research process much more clear.
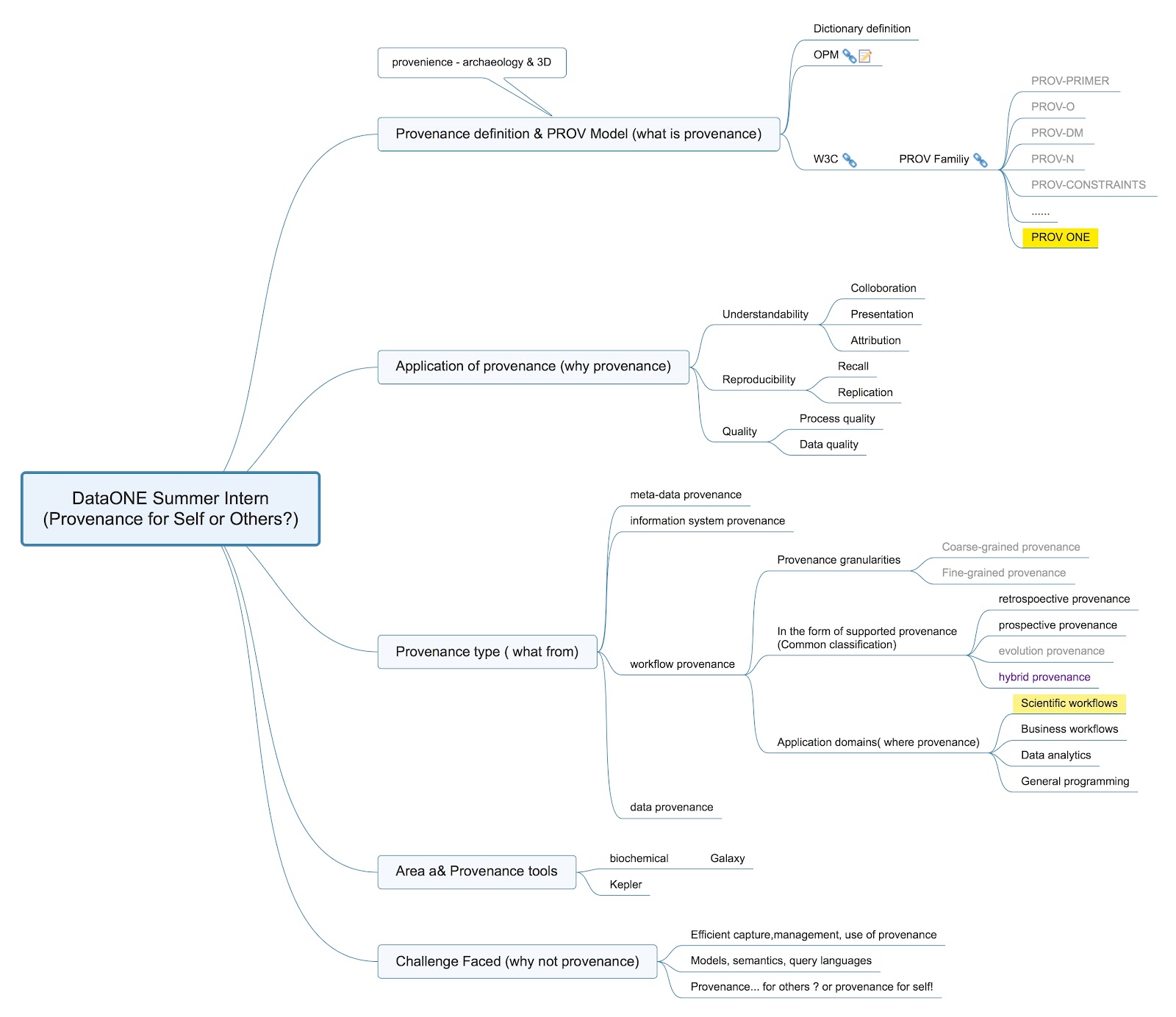
In the previous research, several models have been established to standardize the requirements to create provenance and allow provenance to be exchanged through different systems. The main two models are called OPM and W3C PROV.
OPM
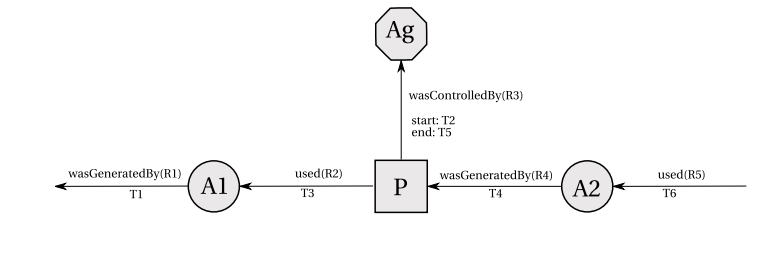
Figure 1 OPM Structure, retrieved from https://eprints.soton.ac.uk/271449/1/opm.pdf
OPM is short for Open Provenance Model, whose aim is to capture the causal dependencies between three concepts, namely artifact (an immutable piece of state), process (actions or series of actions performed on/ by artifacts), agent (Contextual entity acting as a catalyst of a process).OPM is often used to document the previous executions, in other words, the processes happened in the past and they have already ended; in addition, they can still be running.
To understand OPM easily, a graphical notation is often used. Specifically, artifacts are represented by ellipses; processes are represented graphically by rectangles; finally, agents are represented by octagons. In the graph, nodes represent processes, artifacts or agents and edges stands for casual dependencies between nodes.
W3C PROV
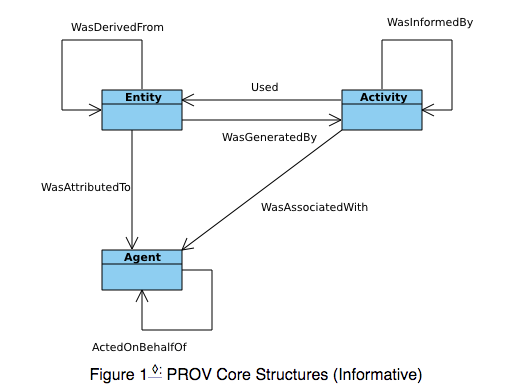
Figure 2 UML Diagram of PROV Structure, retrieved from https://www.w3.org/TR/prov-dm/
Different from OPM, W3C PROV used different terminologies and added more details to the previous models. In PROV, “type” and “relation” are used to represent the “node” and “edge”, furthermore, “entity” and “activity” are corresponding to “artifact” and “process” in OPM. Besides the existed relationships (Used, was generated by, was controlled by, was triggered by, was derived from ), two more relations were added (a dependency between agent and agent, a dependency between entity and agent). Additionally, Mapping of PROV core concepts firstly emerged, which made understanding much easier.
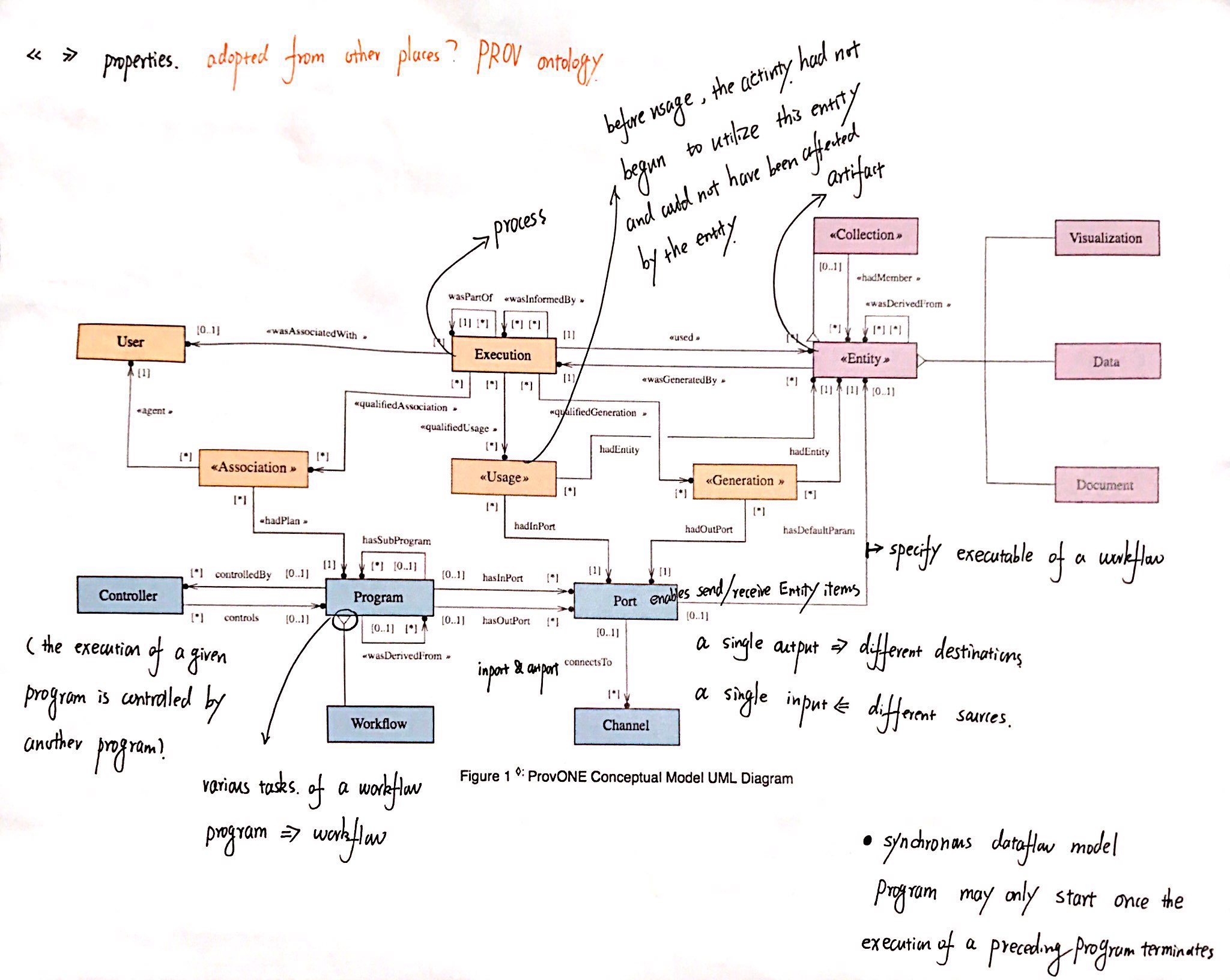
PROV ONE
PROV ONE is defined as an extension of the W3C recommend standard PROV, aiming to capture the most relevant information concerning scientific workflow computational processes, and providing extension points to accommodate the specificities of particular scientific workflow systems.
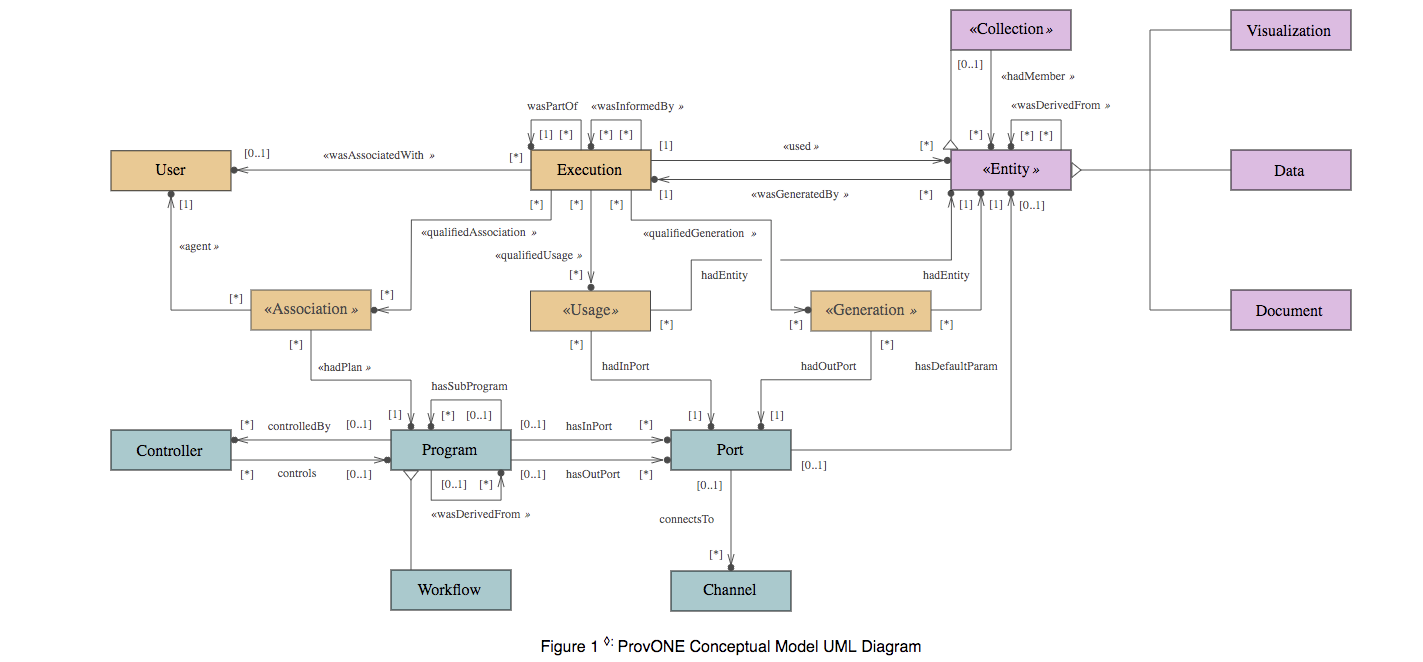
Figure 3 UML Diagram of PROV ONE Model, Cao, Y. at etc. (2016)
Next week, I will discuss with Professor Bertram about the three models above. Furthermore, I will continue read the papers I got yesterday and summarize points about retrospective provenance, prospective provenance and hybrid provenance.
Hope you all have a good weekend.
Reference
Lim, C., Lu, S., Chebotko, A., & Fotouhi, F. (2010, July). Prospective and retrospective provenance collection in scientific workflow environments. In 2010 IEEE International Conference on Services Computing (pp. 449-456). IEEE.
Cao, Y., Jones, C., Cuevas-Vicenttın, V., Jones, M. B., Ludäscher, B., McPhillips, T., … & Walker, L. ProvONE: extending PROV to support the DataONE scientific community.