
The main focus of this week was on translating some of the main provenance queries into Cypher format and compare it with its equivalence in Gremlin.
The first thing to do was to add some proper indexes to our Neo4j database. Currently, we have only one property for each node (name) with an auto_index on it. Depending on the type of queries, we might need to add some other properties of provenance traces to the Neo4j database later. Writing recursive queries for a single node path (e.g. finding parents of a node) in Cypher is quite straight forward and this makes it a perfect choice for writing provenance lineage queries. Figure 1 shows a recursive query for a social networking graph, Figure 2 shows how to find all actors and data artifacts involved in producing a data node, and Figure 3 shows the use a WHERE clause to filter on pattern and return only the data artifacts (this is not a perfect solution in terms of performance issues because it finds the set of all data artifacts and actors and then filters data artifacts from them. I am still looking to see if I can find a way to define a recursive query for paths with more than one relationship or a repeat of a series of pattern matches. In other words, we need to be able to define something like MATCH n-{[:wasGeneratedBy]->()-[:used]}*->a which, with this format, is not supported by Cypher). One simple solution is to add some extra edges to the graph to directly connect each node with its parent data node and skip the actor between them. For example,
n- [: wasGeneratedBy]-> () – [:used]-> a
can be converted to: n – [:wasDerivedFrom] -> a



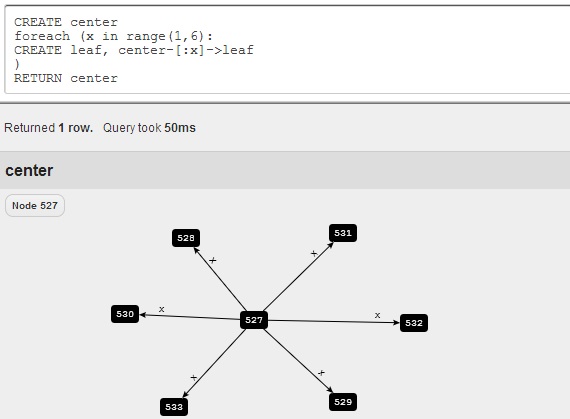
Cypher has some other useful clauses, e.g. SKIP, LIMIT to return a subset of results, WITH for chaining queries together, as well as, CREATE, DELETE, SET for modifying the database. Figure 4 shows a Cypher query that creates a star graph.
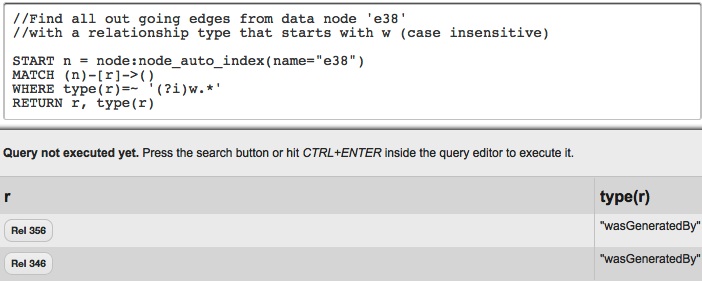
We can also use regular expressions in Cypher’s WHERE clause.
Also, I spent some time on studying two other alternatives for querying graphs: RPQs and Gremlin to see how they compare to Cypher and if they can be used as a complement for Cypher in PBase project.
Gremlin is a graph traversal language written in the Groovy programming language. As opposed to Cypher, Gremlin is an imperative language and is not Neo4j-specific. Gremlin operations are like a series of pipes. Each pipe takes an input collection and pushes a an output collection, where a collection can have one item, many items, or no items, and items are vertices, edges, or property values. For example “outE” takes a collection of vertices as input and outputs a collection of edges. A pipeline is a collection of pipes that expresses what the problem is in a declarative manner. Thus, Gremlin is a language for building pipelines. Below is a simple example for finding actors that were immediately involved in producing “e38” data node:

Gremlin is a traversal-based graph pattern matching language: using “loops” we can traverse other levels of a graph (recursive pattern matching) and “back” enables backtracking.

I find Cypher easier to pick up and more suitable for our provenance queries. “Cypher was created because Neo4j Java API was too verbose, Gremlin is too prescriptive, and SQL is unable to express the path”. However, depending on the future needs of the project, we can also use a mixture of the two as they serve for different purposes. It is also important to note that Gremlin might result in a better performance for larger traces [FP13].
After ProvWG NY meeting, we have a list of general categories of queries that PBase should be able to address. I translated some of those into Cypher and tested them on the current Vistrail trace. Next week, I am going to finalize the queries and run them on some more traces (including traces of multiple run of a Wf). One implicit task will be to gather more traces and convert them to GEOFF format (for that we may need to make some modifications in the current convertor). Neo4j project has a Java code for running Cypher queries which, with some modifications, can of use for running PBase project queries.
All feedback and suggestions for provenance queries are welcome and will be appreciated.
References.
[FP13] Holzschuher, Florian, and René Peinl. “Performance of graph query languages: comparison of cypher, gremlin and native access in Neo4j.” In Proceedings of the Joint EDBT/ICDT 2013 Workshops, pp. 195-204. ACM, 2013.
Hi,
Note that the steps you are using in your Gremlin example are a-typical. For example:
g.V.filter{it.name == ‘a38’}.outE.inV.name
Is simply
g.V.has(‘name’,’a38′).out.name
Next, you don’t need outE.inV.outE.inV. That is simply out.out.
Take care,
Marko.
Thanks for your comment,Yes, you’re right .. I corrected those.. one thing that I couldn’t figure out is how to use “loop” to return all of the grandchildren of a node ..
if I use something like g.V.has(‘name’,’e38′).as(‘x’).out.loop(‘x’){it.loops<5}.name.unique() .. it only gives level 4 .. is there any way to return all of the intermediate levels?