
This week I attended ProvWG meeting at NYU-Poly. This was a two day meeting with the main focus on PBase and D-PPROV [MDB+13], a recent project going on in ProvWG that some of its ideas might be related to PBase project.
D-PPROV is an extension to W3C PROV provenance model aimed at representing process structure. The main theme of the discussion was what are the challenges with the existing PROV model that motivate a new version of it, what kind of questions the users want to pose on provenance traces, and how to map those questions to the model. After a discussion on different classes of users (and their respective use cases), the group concluded that PROV is not sufficient to answer some of these questions and discussed on how D-PROV should be modeled to address those.
The second half of the meeting focused more specifically on PBase project. The main goal of this project is that given a repository of traces presented as data graphs (DAGs), which queries on it can be useful in terms of provenance and how to answer them in an efficient and scalable manner (DAGs can be shown by 〈X, l, Y〉 triples to show node X is connected to Y via an edge labeled l). In other words, PBase stores provenance traces with a new format in order to provide more query capability.
The figure below shows a simple architecture for PBase. Based on this figure, the main phases for PBase project are as follows:
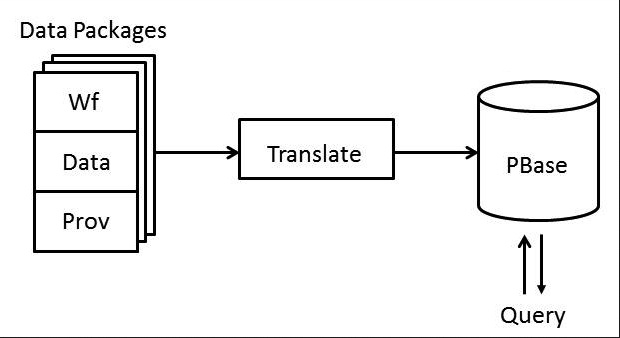
Phase 1: Translate. take provenance data packages as input and produce some databases of our choice. A number of databases were suggested as the PBase database: MongoDB, PostgreSQL, SPARQL, RPQ/2, and Neo4j (a graph database). And there were different suggestions for Tripe-store: Jena, Sesame, 4store, Virtuoso, AllegroGraph. The main criteria in selecting a Triple Store and database for PBase are of compatibility with the existing tools in ProvWG, simplicity, and performance.
Neo4j, an open source, fully transactional, eenterprise-grade NoSQL (Not only SQL) graph database, was selected as the PBase storage because its simplicity makes answering some of the graph queries quite straightforward. Neo4j stores property graphs with nodes that form paths in the graph, directed relationships between them, properties for each node (key and a value), and indexes for look-ups.
“A Graph – records data in -> Nodes – which have -> Properties”
” A Graph Database – manages a -> Graph and – also manages related -> Indexes”
Neo4j is known to be “whiteboard friendly” meaning that if you can draw the design as boxes on a whiteboard, you can store them on Neo4j [RWC12].
Phase 2: Provenance Queries. working on a set of provenance test queries that PBase should be able to answer.
There are several languages that interoperate with Neo4j: Java code, REST, Cypher, Ruby console, and others. The one that we use for this project is Cypher because as it is said on Neo4j tutorial for Cypher,
- it is human readable and expressive
- MATCHes patterns in the graph
- is about the what not how
Phase 3: Test. There are a number of provenance traces repositories that can be used in the test phase of the project. The main suggestions are: Vistrail Provenance traces [CFK+13] , ProvBench, ….
Phase 4: Visualization of the Output. For this phase, we can use Graphviz, Neo4j graph visualization, as well as other graph visualization tools.
In general the meeting was a good experience in that after talking with ProvWG members, I feel like I have a more clear idea about the PBase project goals and how I am going to contribute to PBase project. I will be in contact with my mentors and other ProvWG members by attending ProvWG weekly video conferencing meetings. I left NY city on Tuesday evening with a bad cold as a souvenir but I was lucky enough not to miss my connecting flight to Sacramento after a delay in my flight from NY city.
For the second half on this week I was on a leave from PBase project to attend some events in San Jose. I took an early train from Sacramento and directly headed toward Fairmont San Jose where USENIX WiAC’13 conference was held. This is an annual conference with the main goal of discussing some of the challenges women face in the professional computing world, as well as, networking and sharing ideas. On the rest of my stay in San Jose, I attended WISE (a series of mentoring workshops and talks on privacy and security) at San Jose State University.
In addition, this week I tried to familiarize myself with Neo4j and Cypher by going through some online tutorials/sample queries.
Next week I am going to work on collecting some Wf traces, methods for translating those into Neo4j format, and set up the development environment.
References.
[MDB+13] Missier, Paolo, Saumen Dey, Khalid Belhajjame, Victor Cuevas-Vicenttin, and Bertram Ludaescher. “D-PROV: extending the PROV provenance model with workflow structure.” (2013). [CFK+13] Chirigati, Fernando, Juliana Freire, David Koop, and Cláudio Silva. “VisTrails provenance traces for benchmarking.” In Proceedings of the Joint EDBT/ICDT 2013 Workshops, pp. 323-324. ACM, 2013.
I was searching for the pbase-related sites on Internet and found this one occasionally, I entered the post and went through and … understood nothing !! since in my case, pbase stand for the photography data bank – like here, in my profile 🙂 Iriska